Another Day, Another Outage
Disaster recovery is in the news this week for all the wrong reasons.
Wells Fargo
Stop me if you’ve heard this story before. A major company – in this case a financial institution – is having a technical outage for not only the first, but the second time in less than a week. Assuming you’re not working for Wells Fargo or one of their customers, chances are had a much better time these past few days. These are their recent tweets as of sometime in the afternoon Thursday, February 7. This post went live on Friday morning the 8th and Wells Fargo is still down – basically two days of downtime.
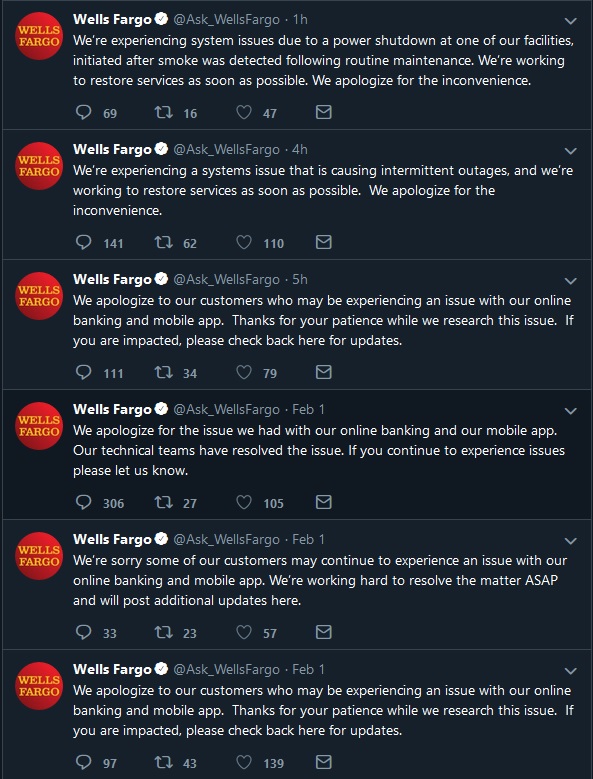
Figure 1. Wells Fargo acknowledging the problem
Ouch. The last tweet is not dissimilar to a British Airways outage back in 2017. This tweet from Wells Fargo claims it is not a cybersecurity attack. Right now that’s still not a lot of comfort to anyone affected.
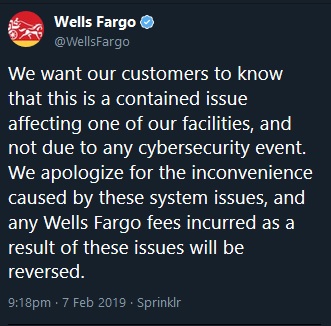
Figure 2. It’s not a hack!
Their customers are not enjoying the outage, either. Three examples from Twitter:

Figure 3. Customer issue due to the outage
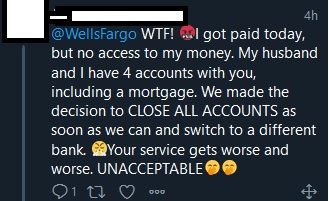
Figure 4. Day two …
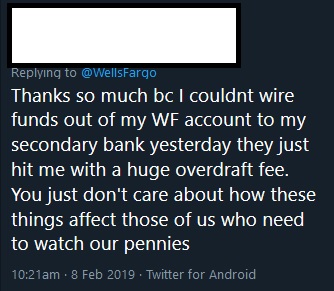
Figure 5. More impact
Imagine the fallout: direct deposit from companies may not work, which means people do not get paid. People can’t access their money and do things like pay bills.For some, this could have a lifelong impact on things like credit ratings if you miss a loan, mortgage, or credit card payment. There is not just the business side of this incident.
There were of course, snarky replies about charging Wells Fargo for fees. I wanted to call out an honest-to-goodness impact to someone along with the possible longer term fallout to Wells Fargo themselves. I feel for the person who tweeted, but the reality is Chase or Citi could have an outage for some reason, too. I don’t think anyone is 100% infallible. I have no knowledge of what those other finanical institutions have in place to prevent an outage.
I’m doing what I do now largely because I lived through a series of outages similar to what Wells Fargo is most likely experiencing this week. Those outages happened over the course of about three months. They are painful for all involved. I worked many overnight shifts, a few 24+ hour days … well, you get the picture. I learned a lot during that timeframe, and one of the biggest lessons learned is that not only do you need to test your plans, but you have to be proactive by building disaster recovery into your solutions from day one. All companies, whether you are massive like Wells Fargo or a small shop has the same issues. The major difference is economy of scale.
Everyone has to answer this one question: how much does downtime cost your business – per minute, hour, day, week? That will guide your solution. Two days in a row of a bank being down is … costly.
There may be another impact, too – can Wells Fargo systems handle the load that will happen when the systems are online again? I bet it will be like a massive 9AM test. Stay tuned!
You don’t want to have a week like Wells Fargo. Take your local availablity as well as your disaster recovery strategy seriously. I’ve always found the following to be true: most do not want do put in place proper diaster recovey until their first major outage. Unfortunately at that point, it’s too late. Once the dust settles, they’ll suddenly buy into the religion of needing disaster recovery. Let me be clear – I do not know what the situation is over at Wells Fargo; zero inside information here. Did they have redundant data centers and the failover did not work? Were some systems redudnant but not others? Were there indications long before the downtime event that they missed? There are more questions than answers, and I’m sure we’ll find out in good time what happened. The truth always comes out.
A Different Kind of Mess – Quadriga
This week also saw a very different problem as it relates to finance: the death of Quadriga CEO Gerald Cotten. Why is his passing away impactful? When he died, apparently he was the only one who knew or had the password for the cryptocurrency vault. There are other alleged issues I won’t get into, but with his laptop encrypted (apparently his wife tried to have it cracked), literally no one whose money was in the vault can get it. The amount stored in there I’ve seen in various stories has been different, but it is well north of $100 million. The lesson learned here is that someone else always needs to know how to access systems and where keys are. Stuff happens – including death. There are real world impacts that can happen when systems cannot be accessed.
Watch Your Licenses
Since we are talking about outages, the Register published a story today about how a system would not come up after routine maintenance due to the software license expiring. I have been through this with a customer. We were in the middle of a data center (or centre, for you non-US folks) migration. We had to reboot a system and SQL Server would not come up. I looked in the SQL Server log. Lo and behold, someone had installed Evaluation Edition and never converted it to a real life. It also meant the system was never patched and never rebooted for a few years! Needless to say, there was no joy in mudville. That was a very different kind of outage.
The Bottom Line
If you do not want to be another disaster recovery statistic and prevent things like the above from happening, contact SQLHA today to figure out where you are and where you need to be.