Five Windows Server 2019 Improvements for SQL Server Deployments
Yesterday I blogged about enhancements to availablity groups in recent updates to SQL Server 2016 and 2017. Today it’s Windows Server’s turn.
Announced last month, Windows Server 2019 will be released later this year. I know there has been a lot of buzz about SQL Server on Linux since SQL Server 2017 was released, but most deployments I see are still on good ol’ Windows Server. There has been no announcement yet which versions of SQL Server will be supported on Windows Server 2019. That said, every version of Windows Server pushes things forward a bit for clustered configurations, and there are three specific improvements that I feel are good for WSFCs and SQL Server in general. All of the features I talked about are in Build 17650 or later which was released on April 24 (yesterday).
There is one new feature right now that I’d love to say works with SQL Server but it doesn’t – cluster sets. I hope they eventually will, but I doubt it will be in Windows Server 2019.
Improvement #1
This one is a general Windows Server improvement that may benefit SQL Server deployments both clustered and non-clustered. I was poking around in setting a server up and formatting some disks. Lo and behold I saw this:
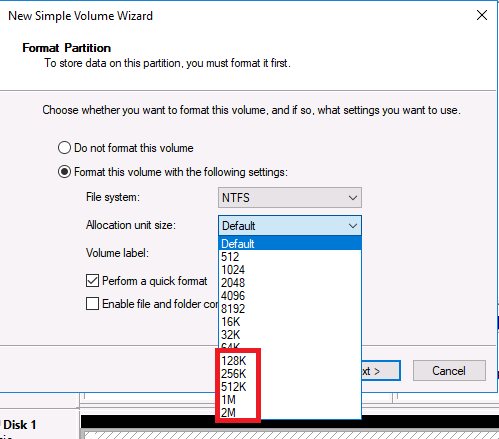
Figure 1. Disk allocations greater than 64K
Your eyes are not deceiving you – disk allocation sizes bigger than 64K! Interesting, no?
Improvement #2
This one is specifically for Always On Failover Cluster Instances (FCIs) that are not using Storage Spaces Direct, but more traditional shared storage. WIndows Server 2016 introduced Storage Replica (SR), but it was only in Datacenter Edition. SR is just Microsoft’s implementation of disk-based replication that works with WSFCs. In Windows Server 2019, SR is coming to Standard Edition. It was introduced in Build 17639. However, there are currently some restrictions which will most likely rule it out for many, namely:
- SR replicates a single volume, not an unlimited number of volumes). So if you have one disk associated with your FCI, it’s great. If you have more than one, not so much.
- You can only have one partnership.
- The volume you are replicating can only be up to 2TB. That is probably the biggest dealbreaker for many SQL Server deployments.
As they note “We will continue to listen to your feedback and evaluate these settings through our telemetry during Insider previews of Windows Server 2019. These limitations may change several times during the preview phase and at RTM.” Make your voices heard – if you want to see this actually useful for SQL Server deployments, provide Microsoft with feedback. Follow the feedback info in the 17639 post I link above. Or just bother Ned Pyle on Twitter. He’ll love it 🙂
Improvement #3
This improvement is for Always On Availablity Groups (AGs). Starting with SQL Server 2016, you could deploy an AG on a Windows Server Failover Cluster (WSFC) without a domain. That particular configuration of a WSFC is called a Workgroup Cluster, but its fatal flaw is that for a witness resource, you were stuck with either a disk (which invalidates the whole non-shared disk deployment model) or cloud witness (which not everyone can use). Well, Windows Server 2019 fixes that problem.
Announced on April 16, you can now use a file share witness (FSW) with a Workgroup Cluster. FSW prior to this specific implementation required a domain, hence the problem in Windows Server 2016. It’s all done with local ACLs on the file share, and when you create the FSW, you provide the credentials. This first screen grab is what you see when you first input the command to create the FSW

Figure 2. Adding a FSW in a Workgroup Cluster
This next one is when it is complete.

Figure 3. FSW successfully configured
All the gory details are in the blog post I link, but this is exciting stuff.
Improvement #4
WSFCs no longer use NTLM and use Kerberos and certificates for authentication. This means that if you’re deploying Windows Server 2019 and your security folks want to disable NTLM, go right ahead.
Improvement #5
Last, and certainly not least, is the one I’m proabably the most excited about. One of the questions I’m asked the most is “How can we change the domain for our FCI or AG configuration?” The answer has been to unconfigure/reconfigure. Going back to the early days of clustering Windows Server, you could not change the domain. That all changes in Windows Server 2019. We finally have the ability to move a WSFC from one domain to another and not have to reconfigure anything! This is big, folks. How to do it from a pure Windows Server perspective is documented here.