Contained Availability Groups in SQL Server 2022
Microsoft announced the public preview of SQL Server 2022 the other day. Along with it comes SSMS 19 Preview 2 which you will need as well. There is no set release date for SQL Server 2022 but with the public preview, we are definitely closer.
One of the features in that announcement is why I am writing this blog post: contained availability groups, yet another AG variant.
For those among you who will call them CAGs, it is not the official abbreviation – it is contained AG. I get it is easier to say or type CAG. Don’t do it unless you want the Allan stink eye (I can already see the memes …).
A Bit of History
The idea of containment is not new to SQL Server. Anyone remember contained databases (or as I like to call them, partially contained databases)? These have been around since SQL Server 2012 but very few have implemented them in the wild. It was a nice concept that basically died on the vine.
Just under two years ago, I got an e-mail from Kevin Farlee (Twitter) asking if I wanted to participate in a private preview for contained AGs. I could not reply fast enough. I played with it and provided some feedback. As is the way these things go, things were silent for a long time. Fast forward to a few months ago when I learned that the contained AG feature was alive and well. It has been very hard for me to not say anything. Kudos to Kevin for pushing this forward and finally getting it into the product.
It shouldn’t have to be said, but don’t bug Kevin. I am fortunate enough to have this type of NDA relationship as well as the trust of both the SQL Server and Windows dev teams. I do what I can behind the scenes to hopefully assist Microsoft to develop better products and experiences for those of you reading this before you even see these features. Some of the features I evaulate or provide feedback on never see the light of day and I will take them to the grave.
Why Do We Need a Contained Availability Group?
All SQL Server availability features except Always On Failover Cluster Instances (FCIs) have a “problem”: when a secondary replica/warm standby/mirror (the term is different for each feature …) takes over as the new boss, some items such as SQL Server Agent jobs, instance level logins, etc., are not there. Going back to the early days of SQL Server when log shipping was not even in the product, this was always a manual process. There are multiple ways to approach this challenge and I am not going to detail them. This “problem” is a longstanding pain point with those who are responsible for managing SQL Server.
Contained AGs solve this issue by having their own master and msdb databases synchronized as part of the AG mechanism.
A Look at Contained Availability Groups
DISCLAIMER All screen shots here are using SSMS 19 Preview 2. Things may change so if what you are seeing in the future is different, that is to be expected.
Contained AGs is not an Enterprise Edition only feature; it will work in Standard Edition (nee Basic AGs) as well.
Right now you can create a contained AG with SSMS or Transact-SQL. In the Availability Group Wizard, Figure 1 shows you two new options.
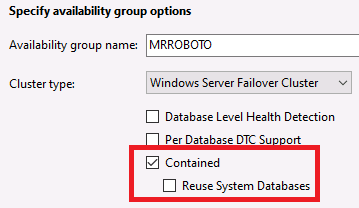
Figure 1. Contained database options in SSMS
For a new AG, you would only have to select Contained. More on the second option in #4 of the gotchas section.
After the contained AG is created, you get two additional databases per AG
- AGNAME_master
- AGNAME_msdb
Figure 2 shows you what the contained databases look like in SSMS.
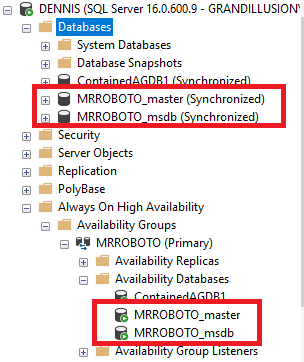
Figure 2. Contained databases
Figure 3 shows you what a contained database looks like on the AG properties dialog. Note that Contained is greyed out and not selectable. See #1 of the gotchas section for more details.
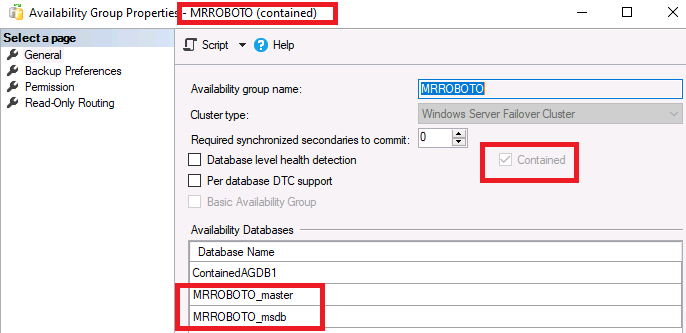
Figure 3. Contained AG properties
You can also see that the AG is contained using the DMV sys.availability_groups as shown in Figure 4 with the new column is_contained.
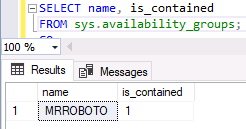
Figure 4. New is_contained column
Create Contained Objects
The contained system databases start out empty except for master which has the administation accounts. That means if you have a lot of logins, jobs, linked servers, etc., they do not automatically move into the contained system databases. You need to create them. How?
- Connect to the contained AG as an administrator.
- Switch to the contained master or msdb.
- Create the object.
The example in Figure 5 creates a login in the contained master database for the MRROBOTO AG and then its corresponding user in the database ContainedAGDB1.
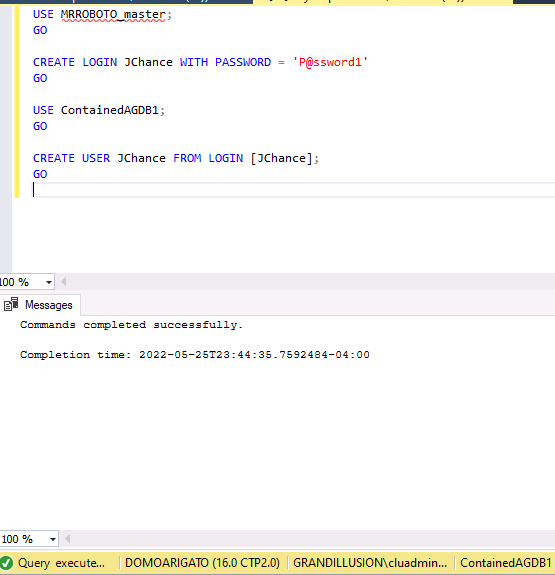
Figure 5. Creating a contained login and the corresponding user in the database
Connect to a Contained Availability Group
Using a contained AG is all about context. If you connect to the instance directly, you only see and can use what is in the instance’s master and msdb databases. Heed gotcha #7 in the next section. Figure 6 shows a connection to a default instance named DENNIS using sqlcmd.
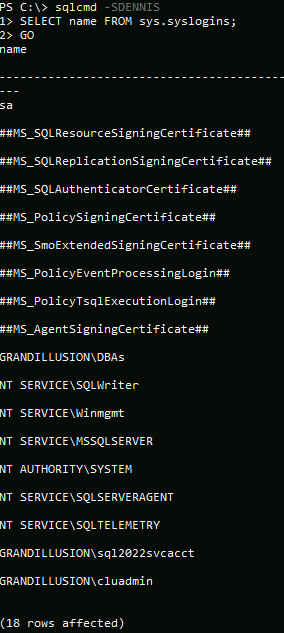
Figure 6. Logins in the instance
If you connect to the contained AG as an administrator, Figure 7 connects to a listener named DOMOARIGATO and shows that in that context, you see a very different set of logins from what was shown in Figure 6. Note JChance that was created earlier is listed.
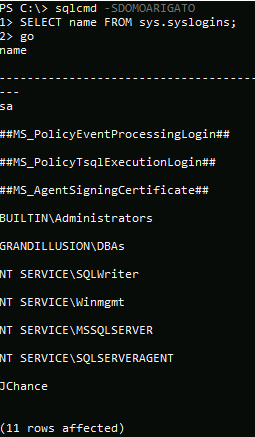
Figure 7. Contained logins
From an application perspective, you can log into the contained AG via the listener with a contained login as shown in Figure 8. JChance gets right in. The syntax used for sqlcmd is:
sqlcmd -Slistenername -Uuserincontaineddatabase -Ppassword
Figure 8. Connect to Listener with Contained User
You can also connect using a combination of a contained user, one of the databases in the contained AG, and the instance (not listener) name. An example is shown in Figure 9 using sqlcmd. The syntax is:
sqlcmd -Sinstancename -Uuserincontaineddatabase -Ppassword -ddatabaseincontainedag
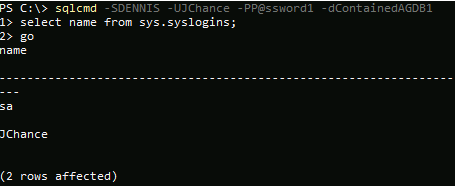
Figure 9. Connecting to a contained database properly
Currently Known Contained Availability Group Gotchas
- An AG can be configured as either contained or not contained (i.e. “regular”). You cannot change an AG’s configuration from not contained to contained or contained to not contained after it is created. To do so, destroy the AG and recreate it the other way. I do not see this ever being changed.
- Contained AGs are not currently supported with distributed AGs. I can think of a few reasons why it would break contained AGs. That means if you rely on distributed AGs today, contained AGs may not be in your future if you want to continue that strategy. My hope is that both contained AGs and distributed AGs work together. If I had to guess, I think it would happen after SQL Server 2022 is released and possibly another major version. I plan on doing some testing to see what does/does not work and if there are workarounds.
- Contained AGs also do not currently work with replication. If you need replication, you may not be able to use a contained AG.
- Contained AGs assume automatic seeding for the AG’s databases including the contained system ones. If you want to create databases via manually seeding (i.e. backup/copy/restore WITH NORECOVERY), use Transact-SQL. The creation process for a contained AG with manual seeding is not documented yet.
- This feature is SQL Server 2022 only. I do not see this being backported to SQL Server 2019. See #1 for implications in an upgrade.
- If you delete the contained AG, it does not delete the contained system databases. If you want to create another AG with the same name, you can choose to reuse those contained system databases already created. That is the second check mark in Figure 1. Otherwise, you will need to manually delete them from all replicas.
- A contained AG is not a security boundary. You can still potentially see everything else in the instance (including the real master and msdb) if you have the access.
- If you do not have a baseline knowledge (not expert) to be able to crate objects not using SSMS, right now contained AGs would be a challenge for you to implement. I am hoping that changes at some point.
My Thoughts
I see contained AGs as a compelling reason to consider upgrading to SQL Server 2022 when it is released. In my opinion, the contained AG feature is the most significant improvement to AGs since the introduction of distributed AGs in SQL Server 2016.
Will contained AGs create world peace? No. Does it fix the external objects outside the database problem for features like log shipping? No; that is still a manual process and a pain point. Does this feature solve an issue that should have been solved with the introduction of AGs in SQL Server 2012 especially for scenarios like automatic failover? Absolutely. Can the feature and its tooling use some improvement? Sure.
The limitation around distributed AGs is more of an understandable disappointment than a dealbreaker for me. The value of this feature is too high not to recommend people kicking the tires on it. I also love distributed AGs so it’s a hard call.
What are your thoughts about contained AGs? Do you have questions about this new feature? Let me know below.